The CFO’s Guide to Agentic AI Costs: From "Cost per Token" to "Cost per Outcome"

It is 2026. You have successfully deployed your first fleet of autonomous agents. They are handling customer support, negotiating procurement deals, and writing code. Then, you get the cloud bill.
The financial model of the "Chatbot Era" (2023-2024) was simple: Humans sent one prompt, the model sent one reply, and you paid for the tokens. The "Agentic Era" (2025-2026) is radically different. A single high-level command from a human— "Analyze our last 5 years of sales data and predict Q3 revenue" —might trigger an agent to:
- Spin up a Code Interpreter environment.
- Query a database 50 times.
- Generate and discard 10 intermediate charts.
- Engage in a "multi-turn loop" that runs for 45 minutes.
You are no longer paying for tokens; you are paying for compute time, memory states, and decision loops. If you apply old FinOps models to this new reality, you will bleed cash. This content hub is your financial survival guide. We move beyond basic "Cost Optimization" to define the new metric for 2026: Cost Per Outcome (CPO).
2. The Strategic Shift: Defining "Cost Per Outcome"
Before you buy tools or tag resources, you must change your philosophy.
- Old Metric (GenAI): Cost per 1k Tokens.
- New Metric (Agentic AI): Cost per Successful Resolution.
If an inexpensive model (like Llama 3 8B) takes 50 loops to solve a coding bug, it is more expensive than a premium model (like GPT-4o) that solves it in 1 loop.
3. The 2026 AI FinOps Landscape (Explore the Hub)
We have broken down the financial engineering of AI agents into five critical battlegrounds. Use these guides to architect a cost-efficient agent fleet.
Phase 1: The Model Pricing Battle
Is it cheaper to use Azure OpenAI, AWS Bedrock, or Google Vertex? Pricing has become intentionally complex. "Provisioned Throughput" (PT) looks expensive upfront but saves millions for high-volume fleets. On-Demand is flexible but punishes consistency. We crunched the numbers for 2026.
Read the Deep Dive: AWS Bedrock vs. Azure OpenAI vs. Google Vertex Pricing Compare Provisioned Throughput vs. On-Demand pricing and see the "Break-Even" point for switching models.Phase 2: The Infrastructure Battle
Should your agents live on Serverless Lambda or Dedicated GPUs? An agent that runs for 100ms is perfect for Serverless. An agent that "thinks" for 20 minutes will bankrupt you on Lambda fees. This guide analyzes the infrastructure layer—the hidden cost of agent memory.
Read the Deep Dive: Serverless Agents (Lambda) vs. Dedicated GPU Instances Analysis of "Cold Starts" vs. "Warm Pools" and when to rent H100s vs. using API endpoints.Phase 3: The Tool Showdown
Which dashboard actually shows you the 'AI Tax'? Generic cloud cost tools (like AWS Cost Explorer) lump all your AI spend into one bucket. You need specialized FinOps tools that can peer inside the API calls to tell you which team's agent is spending the money.
Read the Deep Dive: CloudZero vs. Vantage vs. Native Cost Explorers Review of the top 3 AI-native FinOps platforms and how to track OpenAI spend within Azure subscriptions.Phase 4: The "Tagging" Guide (How-To)
If you can't tag it, you can't bill it. In a fleet of ephemeral agents, resources are created and destroyed in seconds. If you don't automate tagging at the moment of creation, that cost becomes "Unallocated Spend."
Read the Guide: How to Tag AI Resources for Cost Allocation Technical tagging strategies for AWS & Azure and automating tags for ephemeral vector stores.Phase 5: The "Alerting" Guide (How-To)
Stopping the $10,000 Loop. The most dangerous financial risk in 2026 is not high token prices—it is the Infinite Loop. An agent gets stuck trying to fix a bug, retries 5,000 times in an hour, and burns your monthly budget in one night. You need a "Kill-Switch."
Read the Guide: How to Set Up "Runaway Agent" Alerts in AWS & Azure Setting up Anomaly Detection for API spikes and configuring automated "Circuit Breakers."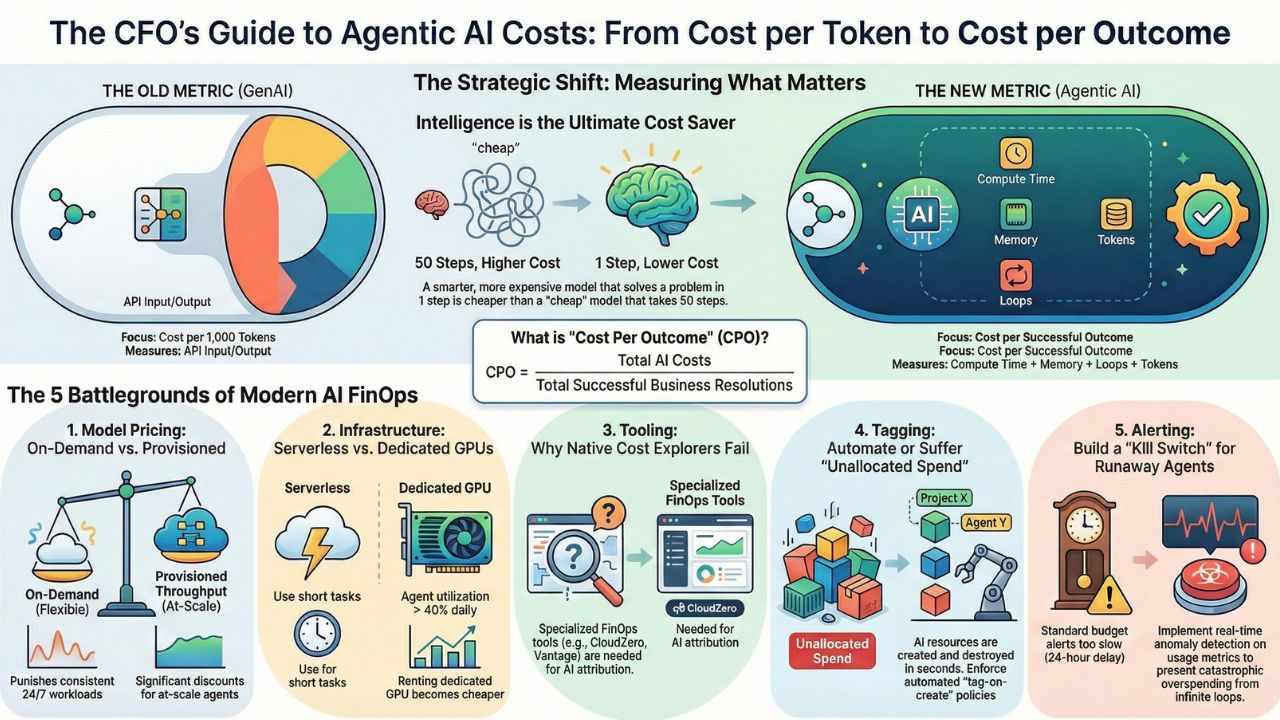
4. Frequently Asked Questions (FAQ)
A: Cloud FinOps optimizes infrastructure (VMs, Storage), while AI FinOps optimizes intelligence (Tokens, Agent Loops, Vector DBs). AI FinOps requires understanding the behavior of the model—because a "bad" model prompt can cause infrastructure costs to spike by 10x.
A: Use the Cost Per Outcome (CPO) formula: CPO = (Total Cost of Compute + Tokens + API Fees) / Total Successful Resolutions. If an agent costs $5.00 to run but replaces a task that costs a human $25.00, the ROI is positive, regardless of the token price.
A: On-Demand pricing fluctuates and has rate limits (TPM). For mission-critical agents, Provisioned Throughput guarantees capacity and offers a fixed price, which is often 30-50% cheaper at scale than On-Demand models.
A: Only for stateless agents or batch processing. If an agent is maintaining a long-term "memory" or context window, a Spot interruption will wipe its memory, forcing it to restart the task and doubling your cost.
