AWS Bedrock vs. Azure OpenAI vs. Google Vertex: The 2026 Pricing Battle

In 2024, the choice of an AI provider was often technical: "Who has the best model?" By 2026, the models have commoditized. Claude, GPT-4o, and Gemini Ultra trade blows on the leaderboard weekly. The new differentiator is not IQ—it is the invoice.
This technical comparison is part of our wider CFO’s Guide to Agentic AI Costs. We are moving beyond the marketing fluff to compare the hard costs of running 24/7 autonomous agents on the "Big Three" clouds.
1. The Philosophy of Pricing: Aggregators vs. Native
To understand the bill, you must understand the architecture.
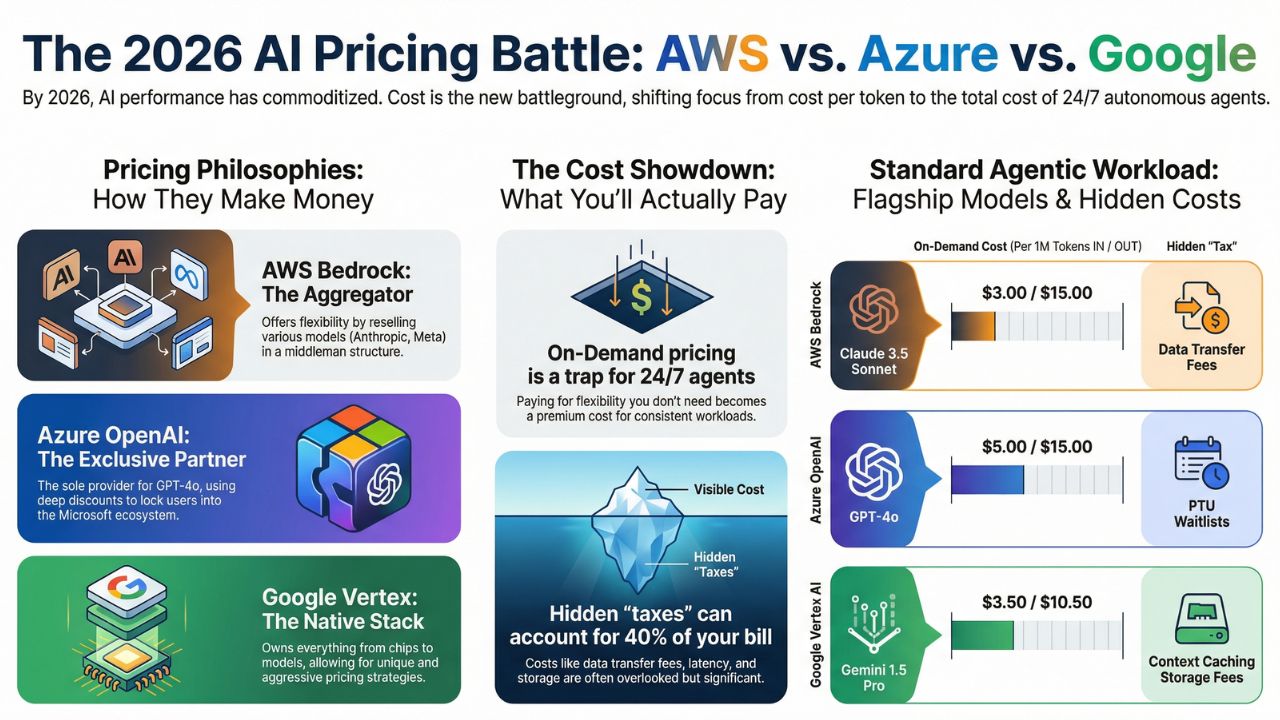
- AWS Bedrock (The Aggregator): Amazon does not own the models (mostly). They resell Anthropic, Cohere, and Meta. Their pricing reflects a "middleman" structure but offers the best flexibility.
- Azure OpenAI (The Exclusive): Azure is the only home for GPT-4o. Their pricing is designed to lock you into the Microsoft ecosystem with heavy discounts for committed use (PTUs).
- Google Vertex (The Native): Google owns the entire stack, from the TPU chips to the Gemini model. This allows them to offer aggressive "Context Caching" discounts that AWS and Azure struggle to match.
2. The Comparison Matrix: On-Demand vs. Provisioned
The following table breaks down the 2026 pricing for a standard "Agentic Workload" (Input heavy, Output light, high frequency).
| Feature | AWS Bedrock | Azure OpenAI | Google Vertex AI |
|---|---|---|---|
| Flagship Model | Claude 3.5 Sonnet | GPT-4o | Gemini 1.5 Pro |
| On-Demand Cost (Per 1M Input/Output) |
$3.00 / $15.00 | $5.00 / $15.00 | $3.50 / $10.50 |
| Provisioned Throughput (PT/PTU) |
Hourly Commit (Expensive short-term) |
Monthly Commit (Cheapest for scale) |
Per-Second Billing (Most Flexible) |
| Hidden "Tax" | Data Transfer Fees (if cross-region) | PTU Waitlists | Context Caching Storage |
| Best Use Case | Multi-Model Agents | Enterprise Monoliths | Long-Context Analysis |
3. The "Hidden" Costs: Latency and Egress
The price per token is only 60% of your bill. The remaining 40% comes from infrastructure inefficiencies.
The Cost of Latency
Time is money. Azure's GPT-4o is powerful, but during peak hours in US-East, latency can spike. An agent waiting 3 seconds for a response is an agent that is holding open a memory state, consuming RAM on your hosting layer.
The Multi-Cloud Egress Trap
If your data lives in AWS S3, but you are querying Azure OpenAI, you are paying "Egress Fees" for every gigabyte of data sent to Azure. For RAG (Retrieval Augmented Generation) pipelines, this can add $0.09 per GB, destroying your margins.
Next Step: Stop the Bleeding Once you choose a provider, ensure you set up runaway agent alerts to prevent infinite loops from draining your budget.4. Provisioned Throughput (PT): The Break-Even Math
When should you switch from "Pay-as-you-go" to "Provisioned Throughput"?
The Formula: If your agents are consuming more than 300,000 Tokens Per Minute (TPM) for at least 6 hours a day, Provisioned Throughput becomes cheaper.
Azure PTUs: Azure requires a 1-month commitment minimum for PTUs. This is a risk if your agent traffic is "spiky."
AWS Provisioned: AWS allows for shorter commitment windows but requires you to "reserve" model units, which can be complex to calculate.
5. Frequently Asked Questions (FAQ)
A: As of 2026, Azure OpenAI offers the most competitive rates for GPT-4o due to their exclusive partnership and optimized "Regional PTU" (Provisioned Throughput Units), which can offer up to 40% savings compared to standard pay-as-you-go rates for high-volume users.
A: For most enterprise fleets, the break-even point occurs at approximately 300,000 tokens per minute (TPM) running consistently for 8+ hours a day. Below this volume, On-Demand pricing is generally cheaper.
A: No, AWS Bedrock is serverless for inference. You do not pay for hosting the base models (like Claude 3.5 or Llama 3). You only pay for the input/output tokens processed, unless you opt for Provisioned Throughput to guarantee capacity.
