Serverless Agents (Lambda) vs. Dedicated GPU Instances: Which is Cheaper for 24/7 Bots?

In the early days of Generative AI, everything was an API call. But as we move into the "Agentic Era" of 2026, the architecture is changing. Agents are not just calling models; they are running complex loops, maintaining memory states, and executing code.
This infrastructure deep dive is a core component of our CFO’s Guide to Agentic AI Costs. Today, we answer the most common question from Engineering Leads: "Should I run my agents on Serverless Lambda or rent a box with an H100?"
1. The Core Conflict: Stateless vs. Stateful
To make the right financial decision, you must understand the nature of your agent's workload.
- The "Router" Agent (Serverless Friendly): Quick, snappy decisions. "Look at this email, categorize it as Spam or Legit, and shut down." It runs for 200ms. Perfect for AWS Lambda.
- The "Worker" Agent (GPU Friendly): Deep, long-running tasks. "Ingest this 50-page PDF, compare it to our policy database, and draft a response." It might "think" for 45 seconds or keep a memory window open for 10 minutes. This will bankrupt you on Serverless.
2. The Break-Even Analysis: The 40% Rule
We have analyzed thousands of agent hours across AWS and Azure. The financial "tipping point" is surprisingly consistent.
Scenario A: The Serverless Bill Shock
AWS Lambda charges you for Duration x Memory. If you run a high-memory agent (needed for large context windows) that runs for 15 minutes to solve a coding bug, you are paying a premium rate for every millisecond of that "thinking time."
Scenario B: The Dedicated Instance
Renting an AWS `g5.2xlarge` (NVIDIA A10G) costs roughly $1.20 per hour (On-Demand). You pay this whether the GPU is idle or sweating.
| Metric | Serverless (Lambda/Cloud Run) | Dedicated GPU (EC2/VM) |
|---|---|---|
| Cost Model | Pay per Millisecond | Pay per Hour |
| Idle Cost | $0.00 | $1.20/hr (even if sleeping) |
| Cold Starts | High (5s - 30s latency) | None (Always hot) |
| Best For | Spiky Traffic (Chatbots) | Consistent Workloads (Data Processing) |
3. The "Spot Instance" Trap
CFOs often ask: "Can't we just use Spot Instances to save 90%?"
Do not do this for stateful agents.
Spot instances can be reclaimed by the cloud provider with a 2-minute warning. If your agent is in step 45 of a 50-step reasoning chain, and the server dies, the agent loses its "memory." It has to restart the job from scratch. You haven't saved money; you've doubled your compute cost and destroyed the user experience.
Compare Model Costs: AWS Bedrock vs. Azure OpenAI Once you've sorted the infrastructure, check which model provider offers the best price per token.4. The Hidden Killer: "Cold Starts" in Agent Chains
In an "Agentic Workflow," one agent often calls another. Agent A (Manager) calls Agent B (Coder). If Agent B is on Serverless and hasn't run in a while, it must "Wake Up."
Loading a modern LLM context into memory can take 10-30 seconds. If you have a chain of 5 agents, and they all hit cold starts, your user waits 2 minutes for a "Hello." This is why Enterprise production fleets almost always move to Provisioned Concurrency or Dedicated GPUs eventually.
Next Step: Tracking the Spend See which FinOps tools can actually visualize these "Cold Start" costs and attribution.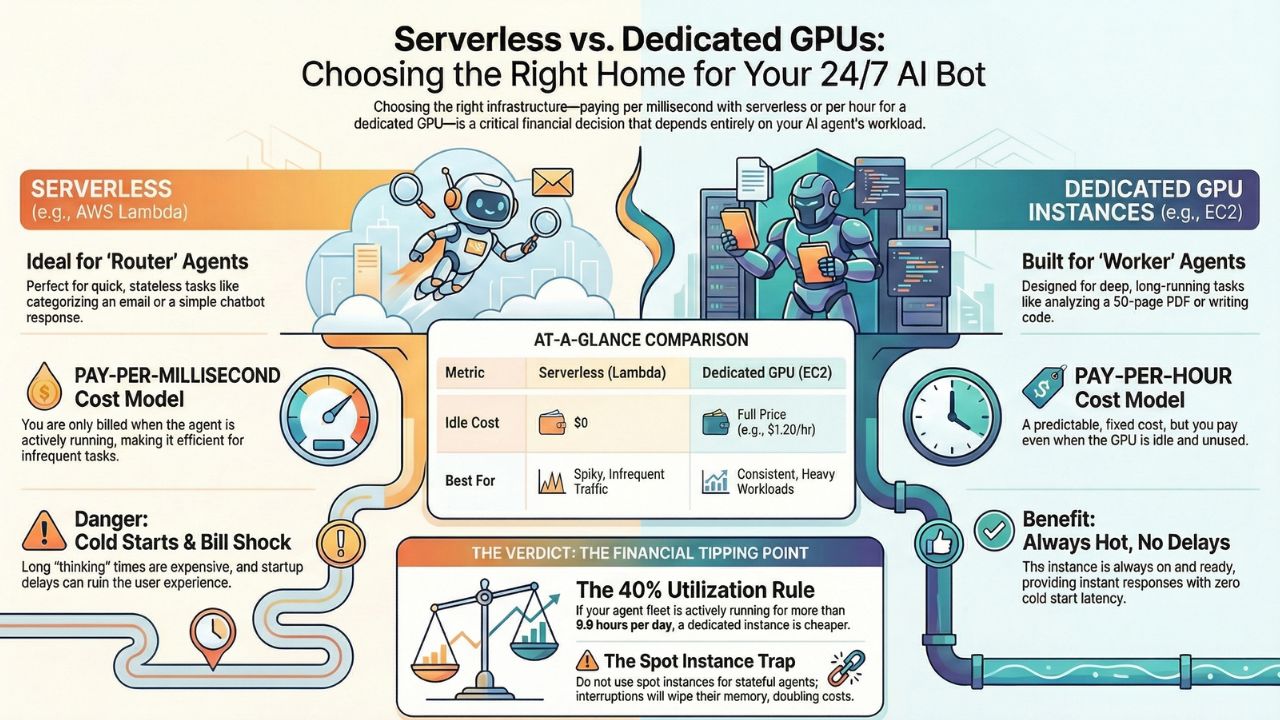
5. Frequently Asked Questions (FAQ)
A: The general rule of thumb for 2026 is the 'Utilization Threshold'. If your agent fleet is running inference (thinking) for more than 40% of the day (approx. 9.6 hours), renting a dedicated GPU instance becomes cheaper than paying per-millisecond serverless fees.
A: Spot Instances are cheap but volatile. If an agent is in the middle of a complex multi-step reasoning task (holding context in memory), a Spot interruption will wipe that memory. The agent must restart the entire chain, doubling your costs.
A: Serverless functions 'sleep' when unused. When an agent is triggered, the cloud provider must spin up the container and load the model weights. For large LLMs, this 'Cold Start' can take 5-30 seconds, causing unacceptable delays.
