Pinecone vs. Weaviate vs. Milvus for Enterprise RAG
Autonomous agents differ from simple chatbots because they remember. They require long-term memory to execute multi-step workflows, and this memory lives in the Vector Database. Without a robust retrieval layer, your "smart" agent is just a stateless text generator.
This infrastructure layer can quickly become a hidden cost center if not optimized for scale. Indian CIOs often start with a simple prototype, only to find their monthly cloud bills exploding as they scale to millions of vectors.
In this guide, we compare the Total Cost of Ownership (TCO) of managed vector databases versus self-hosted options, focusing strictly on scalability and latency for high-throughput agent workflows. We analyze the "Big Three" of the vector world: Pinecone, Weaviate, and Milvus.
1. The Core Decision: Managed vs. Self-Hosted
Before selecting a vendor, you must choose an architecture. The trade-offs between self-hosted vs managed vector db for agents are significant.
- Managed (Pinecone): Zero operational overhead. You pay a premium for "serverless" ease. Best for teams who want to move fast without DevOps.
- Self-Hosted / Hybrid (Weaviate/Milvus): You run the open-source version on your own Kubernetes cluster (e.g., EKS or AKS in India regions). This drastically lowers software licensing costs but increases engineering salary costs.
2. Pinecone: The "Serverless" Standard
Pinecone is the default choice for many because it "just works." Its serverless architecture means you don't provision pods; you just pay for what you store and read.
The Cost Reality
While easy to start, Pinecone's costs can scale linearly. For high-throughput agent memory solutions, where an agent might read/write memory 50 times per task, consumption charges add up.
3. Weaviate: The "Hybrid" Flexible Choice
Weaviate stands out for its flexibility. It offers a managed cloud service but is also popular as a self-hosted option. Its "hybrid search" (combining vector search with traditional keyword search) makes it excellent for enterprise RAG where exact keyword matches (like Invoice IDs) are crucial.
The Cost Reality
Weaviate allows you to control the hardware. If you run it on your own Azure India instance, you avoid the markup of a managed service, paying only for the raw compute and storage.
4. Milvus: The "Scale" Choice
Milvus (and its managed service, Zilliz) is architected for massive scale. If your roadmap involves storing billions of vectors (e.g., a bank storing vector embeddings of every transaction for fraud detection), Milvus is the heavyweight champion.
The Cost Reality
We analyze Milvus managed service pricing for those preferring open-source roots. While the setup is more complex than Pinecone, the TCO per million vectors drops significantly as volume increases.
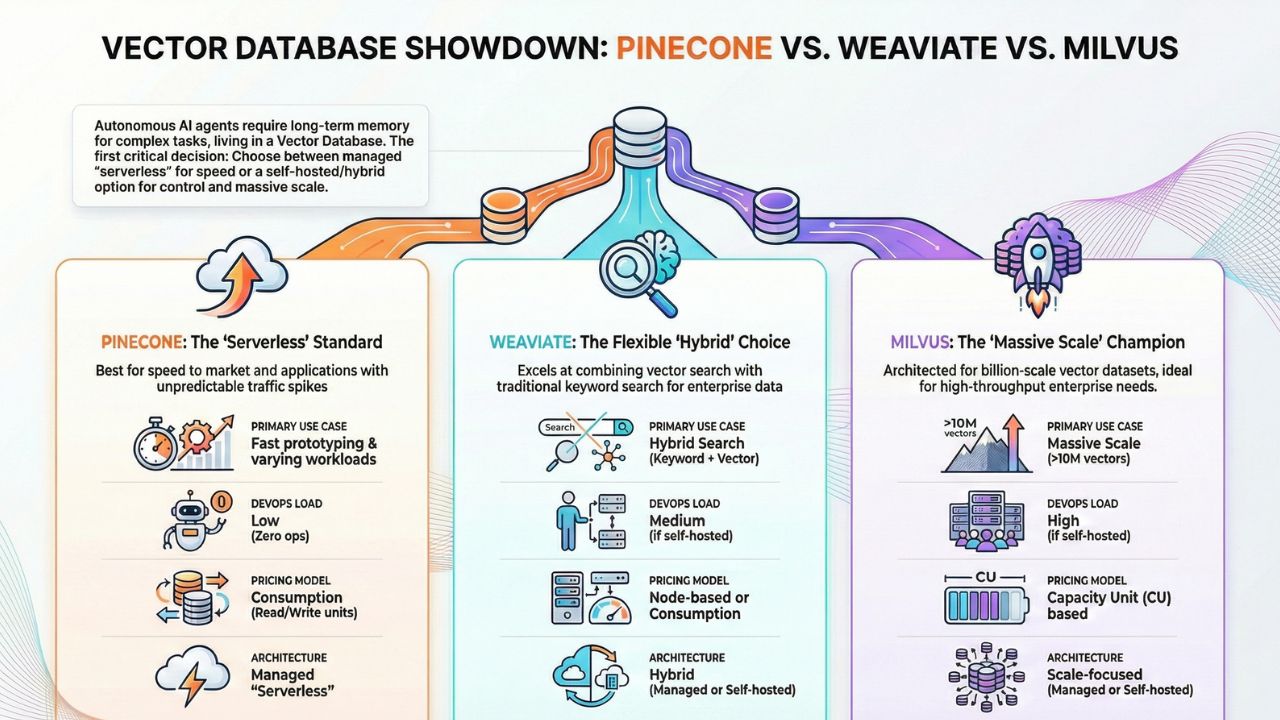
5. Comparative Analysis: TCO & Latency
Below is a summary of our analysis on real vector database TCO India when scaling to millions of vectors.
| Feature | Pinecone (Serverless) | Weaviate (Hybrid) | Milvus (Scale) |
|---|---|---|---|
| Primary Use Case | Fast prototyping & varying workloads | Hybrid Search (Keyword + Vector) | Massive Scale (>10M vectors) |
| Pricing Model | Consumption (Read/Write units) | Node-based or Consumption | CU (Capacity Unit) based |
| DevOps Load | Low (Zero ops) | Medium (if self-hosted) | High (if self-hosted) |
| Latency | Consistent, low latency | Tunable based on hardware | Optimized for high throughput |
Frequently Asked Questions (FAQ)
A: For massive scale, Milvus (specifically its managed version, Zilliz) is architected for high-throughput and billion-scale vector datasets.
A: Pinecone offers a serverless "starter" tier that is often free or very low cost for prototyping, making it the easiest entry point before scaling.
A: Self-hosting (e.g., Weaviate or Milvus on AWS Mumbai) gives you full control over data residency and can lower TCO at scale, but it requires dedicated DevOps resources.
