AWS Bedrock vs. Azure OpenAI vs. Google Model Garden Pricing

Inference is the electricity of the agentic economy. Running open-source models (like Llama 3) on private clouds versus utilizing proprietary APIs involves complex math regarding token consumption and "Green FinOps."
For Indian CIOs, the "FinOps" decision is no longer just about cloud storage; it's about optimizing the cost of intelligence. An autonomous agent that runs 24/7 can easily rack up a bill that exceeds a human salary if the underlying compute layer isn't chosen carefully.
This guide provides a breakdown of the hidden costs of running models on AWS Bedrock vs Azure OpenAI pricing India. We also include a critical look at Google Model Garden enterprise costs and the financial realities of running Llama 3 on private cloud.
1. The "Token Economics" of Agents
Unlike simple chatbots, agents operate in loops. A single user request ("Plan my travel") might trigger 10-50 internal thought steps, database queries, and self-corrections. This "Multi-Turn Overhead" kills budgets.
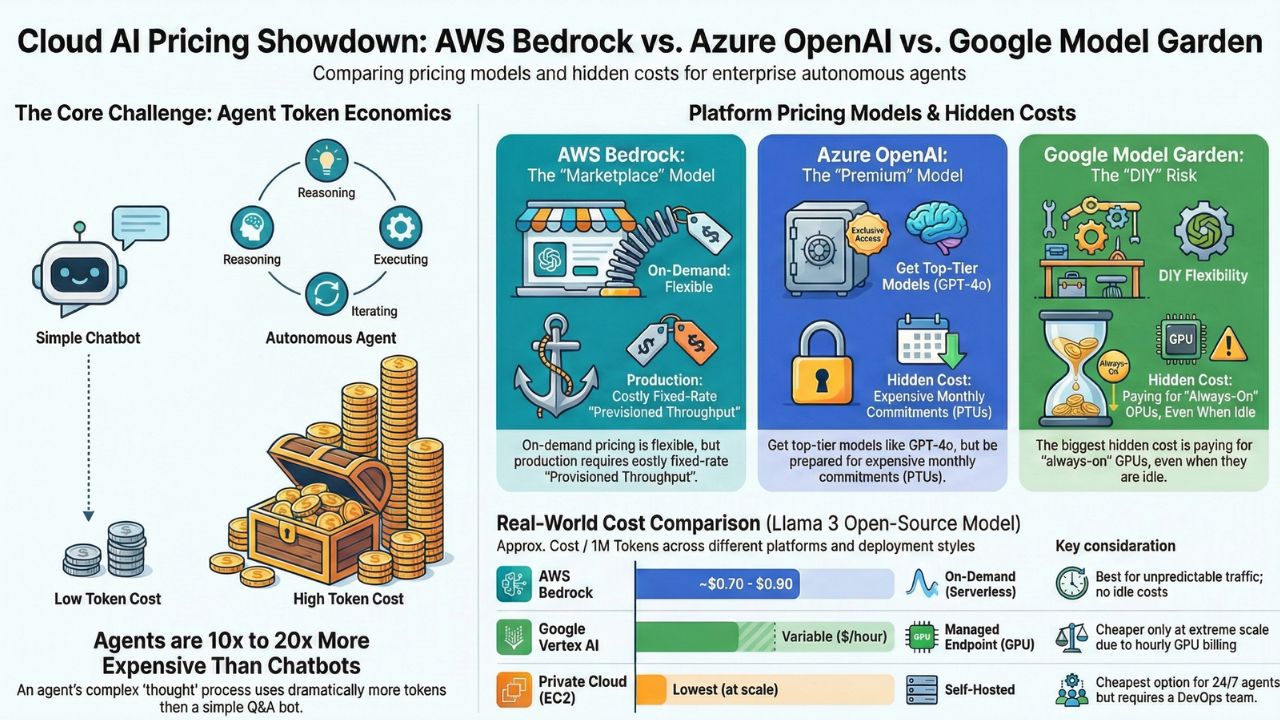
2. AWS Bedrock: The "Marketplace" Model
AWS Bedrock offers a "Serverless" experience for open-source models (Llama, Mistral) and proprietary ones (Claude, Titan). You pay only for what you use.
Hidden Costs
While "On-Demand" pricing is attractive for pilots, Bedrock's Provisioned Throughput is essential for production agents to guarantee speed. However, this locks you into a fixed hourly rate (e.g., $20-$80/hour depending on model units) regardless of traffic.
3. Azure OpenAI: The "Premium" Model
Azure gives you exclusive access to GPT-4o. The performance is unmatched, but so is the price tag.
The PTU Trap
For enterprise-scale, Microsoft encourages purchasing Provisioned Throughput Units (PTUs). In India, a minimum PTU commitment can run into thousands of dollars per month. It stabilizes latency but requires high, consistent utilization to be cost-effective vs. Pay-As-You-Go.
4. Google Vertex AI Model Garden: The "DIY" Model
Google's Model Garden allows you to deploy open-source models like Llama 3 or Gemma on your own managed infrastructure.
The Idle Cost Risk
Unlike Bedrock's serverless inference for Llama, Vertex AI often requires you to "deploy to an endpoint." This spins up a VM with a GPU (e.g., L4 or A100). You pay for this node per hour, even if no one is talking to your agent. This is the "Green FinOps" killer—burning carbon and cash on idle GPUs.
5. Price Showdown: Llama 3 (70B) Inference
Comparing the cost to process 1 Million Tokens (Input + Output mix).
| Platform | Deployment Mode | Approx Cost / 1M Tokens | Pros/Cons |
|---|---|---|---|
| AWS Bedrock | On-Demand (Serverless) | ~$0.70 - $0.90 | No idle costs. Best for spiky traffic. |
| Google Vertex AI | Managed Endpoint (GPU) | Variable ($/hour) | Cheaper at high scale (>100M tokens/day), expensive for low scale due to hourly GPU billing. |
| Private Cloud (EC2) | Self-Hosted (g5.48xlarge) | Lowest (at scale) | Requires DevOps team. Best for 24/7 background agents. |
6. Token Economics Calculator
Use this logic to estimate your monthly spend:
Simple Monthly Cost Estimator
(50 agents * 20 tasks * 2000 tokens * 30 days)
Cost on GPT-4o: ~$900/month
Cost on Llama 3 (Bedrock): ~$50/month
Frequently Asked Questions (FAQ)
A: For sporadic workloads, Bedrock's on-demand pricing is cheaper. However, if you have sustained high throughput (24/7 agents), hosting Llama 3 on provisioned EC2 instances (using SageMaker or direct EC2) can be 30-40% cheaper at scale.
A: Yes, Azure OpenAI offers Provisioned Throughput Units (PTUs) in India regions, which allows for predictable performance and cost for high-volume enterprise applications.
A: The hidden cost often lies in the "always-on" infrastructure. Unlike serverless APIs, deploying a custom Llama 3 endpoint in Model Garden requires keeping a GPU node running, incurring hourly costs even when idle.
