Data Mesh vs. Data Fabric: Architecting for Agentic AI
Back to AI-Native Infrastructure Strategy Hub
Quick Navigation:
The transition from Generative AI (chatbots) to **Agentic AI** (autonomous systems) marks a complete paradigm shift, forcing a fundamental rethink of the enterprise data architecture. AI Agents are not simple API calls; they are stateful, goal-oriented entities that must reason across every data silo in your organization.
Traditional data models—the Data Warehouse (DW) and Data Lake (DL)—were built for human analysts and batch reporting. They fail the agentic test on three critical axes: **latency**, **contextual depth**, and **data coverage**.
The Contenders: Data Mesh vs. Data Fabric
To feed the hungry Agentic AI, modern enterprises are converging on two leading architectural patterns. The choice between them dictates the agility and scale of your entire AI initiative.
Data Mesh: The Organizational Approach
Data Mesh is a socio-technical principle focused on decentralization, popularized by Zhamak Dehghani. It is built on four core pillars:
- Domain Ownership: Data is owned and managed by the business domain that generates it (e.g., the Sales team owns Customer Data).
- Data as a Product: Data domains must treat their data like a product, offering high quality, discoverability, and clear SLAs.
- Self-Serve Data Platform: A central platform team provides the tools for domain teams to create and publish their data products.
- Federated Governance: Global rules are enforced locally by domain teams.
The Agentic Challenge for Data Mesh: While excellent for human analytics, Data Mesh's focus on independence can create interoperability friction for an AI agent. An agent needs a seamless, unified view of the enterprise, not a fragmented catalogue of products it must manually stitch together.
Data Fabric: The Metadata-Driven Solution
Data Fabric is an architectural approach that focuses on a unifying layer of intelligent metadata. It keeps the data physically distributed in its source systems (DW, DL, operational DBs) but creates a virtual, real-time access layer using advanced capabilities:
- Intelligent Metadata: A knowledge graph or catalog automatically discovers, profiles, and connects data across the enterprise.
- Automated Integration: Tools like virtualization and ingestion automation eliminate manual ETL/ELT pipelines.
- Unified Access: It creates a single access point for all users and, critically, all AI agents, regardless of where the data resides.
Why Data Fabric is AI-Native: Data Fabric is inherently more suitable for Agentic AI because it provides a unified, highly contextualized view of the enterprise without duplicating data or relying on domain teams to build perfect "data products." The agent queries the Fabric, and the Fabric automatically computes the answer from the disparate sources in near real-time.
Gartner recognizes Data Fabric's accelerating path towards mainstream adoption, driven primarily by the complex data requirements of generative AI projects in the 2025 Hype Cycle for Data Management.
The Agent's Semantic Memory: Vector Databases & RAG
Regardless of the architectural choice (Mesh or Fabric), a new component is non-negotiable for Agentic AI: the **Vector Database**. This is the specialized storage system that provides the agent with semantic (meaning-based) memory.
Vector Databases: Storing Meaning, Not Rows
Traditional databases (like SQL or NoSQL) index data by keywords or columns. They are excellent for transactional lookups ("Show me Order ID 405"). Vector Databases store data as high-dimensional **embeddings** (vectors) that represent the *meaning* of the data. This enables the agent to search for context:
- Contextual Search: Querying for "employee dissatisfaction" will retrieve relevant documents, emails, and survey results, even if the exact phrase "employee dissatisfaction" isn't used.
- Agent State Management: Agents use Vector DBs to store their past actions, tools, and results, allowing them to maintain a state across long-running, multi-step workflows.
RAG Architecture Best Practices
Retrieval-Augmented Generation (RAG) is the methodology that leverages the Vector DB to give your LLM verifiable context. This is the enterprise-grade defense against LLM **hallucination**.
- Preprocessing is 80% of the Work: Convert all your unstructured data (PDFs, call logs, proprietary manuals) into clean, high-quality text chunks. Use techniques like recursive chunking and metadata tagging.
- Vector Quality (Embeddings): Do not use free or public embedding models for private data. Invest in a state-of-the-art embedding model that is specifically trained for your domain (e.g., legal or finance).
- Multi-Hop RAG: For complex agentic tasks, implement Multi-Hop RAG, where the agent performs multiple searches against the Vector DB and iteratively refines its plan based on the retrieved facts before providing a final answer.
Technology Landscape: Preparing for AI-Ready Data in India
The choice of platform is often between the established Data Warehouse (like Snowflake) and the modern Data Lakehouse (like Databricks).
| Criteria | Data Warehouse (Snowflake) | Data Lakehouse (Databricks) |
|---|---|---|
| AI Agent Data Flow | Best for structured, clean, historical data access. | Best for unified structured, unstructured, and streaming data for training and RAG. |
| Unstructured Data Support | Requires external tools for full text and vector indexing. | Native support for large files and integrated vector search capabilities. |
| Sovereign AI Readiness | Strong cloud-agnostic options; increasing support for private cloud/VPC deployments. | Open-source core technologies (Delta Lake) and a strong history of on-prem/private deployment control. |
Data Governance for Autonomous Agents
The rise of Agentic AI creates an immediate, critical need for **Agentic Data Governance**. An agent acting autonomously must adhere to the same Data Protection and Privacy (DPDP) policies as a human employee.
Your Data Fabric must incorporate a robust policy engine that controls:
- Tool Permissioning: What APIs (Tools) can the agent call? (e.g., Can the agent access the HR salary database?)
- Data Masking: Can the agent redact PII (Personally Identifiable Information) before it is sent to the LLM for processing?
- Audit Trails: Every action and decision made by an AI agent must be logged for compliance and explainability.
This is the final checkpoint to ensure your AI-Ready Data Architecture is compliant and trustworthy in the highly regulated Indian enterprise environment.
Continue Reading: Sovereign AI & India Strategy How to leverage this data architecture for DPDP compliance and on-prem deployment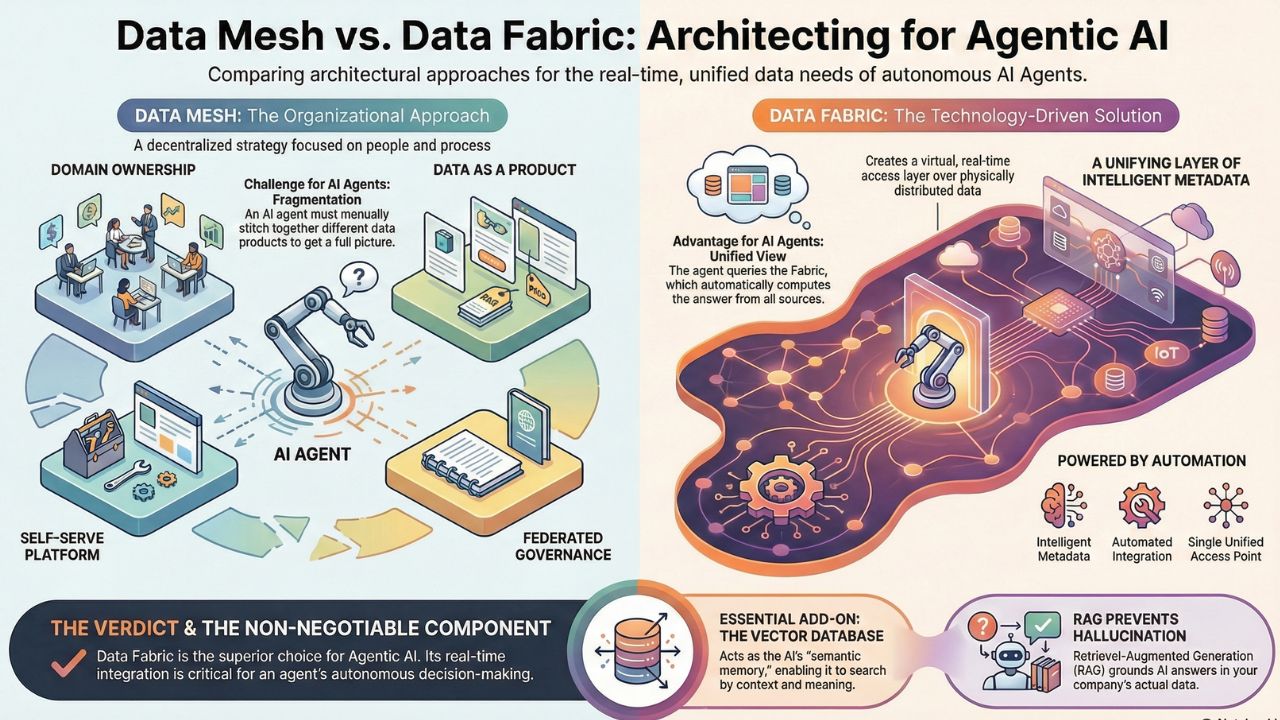
Cost-Benefit Analysis for GCC Leaders
For Global Capability Center (GCC) leaders, transitioning from legacy data silos to an AI-ready Data Fabric or Mesh requires a rigorous ROI breakdown. The implementation of Agentic AI creates a massive influx of unstructured data processing, which fundamentally shifts cloud expenditure.
The Implementation Strategy: Rather than attempting a "rip-and-replace" of your entire data warehouse, GCCs should adopt a hybrid integration strategy. By layering a metadata-driven Data Fabric over existing operational databases, teams can achieve the real-time data access required by RAG without migrating petabytes of historical data.
- Cost Reduction: A unified Data Fabric significantly reduces the compute costs associated with redundant ETL pipelines and data duplication, often lowering storage overhead by up to 30%.
- Accelerated Time-to-Market: Giving AI agents immediate, governed access to a semantic layer reduces the time software engineers spend writing custom API connectors, accelerating enterprise AI deployment cycles from months to weeks.
- Security ROI: Centralized agentic data governance minimizes the risk of PII leakage in LLM prompts, preventing costly regulatory fines under frameworks like India's DPDP Act.
Frequently Asked Questions (FAQ)
A: Data Fabric is often the superior architectural choice for Agentic AI. While Data Mesh promotes good data ownership, Data Fabric's core strength lies in its metadata-driven, real-time integration layer, which allows agents to access and correlate data across silos automatically and instantly—a necessity for autonomous decision-making.
A: Vector Databases function as the agent's long-term, semantic memory. They store high-dimensional embeddings of all enterprise data, allowing the AI to query for concepts and context (e.g., 'What is the policy on leave?'), rather than relying on exact keyword matching, which is crucial for RAG.
A: RAG works by first retrieving the most relevant, verifiable documents from the Vector Database (the Retrieval step) and then feeding that context into the LLM alongside the user's prompt (the Generation step). This grounds the model's output in the enterprise's private data, drastically reducing the chance of generating inaccurate or made-up information (hallucinations).
