Sovereign AI & Small Language Models (SLMs): The India Strategy
Back to AI-Native Infrastructure Strategy Hub
For the past three years, "AI Strategy" in India often meant "How do we wrap a UI around the GPT-4 API?". As we enter 2026, that strategy is dead. The convergence of strict data laws and the rise of capable open-source models has created a new mandate: Sovereign AI.
With the IndiaAI Mission officially launching the nation's sovereign foundation model in February 2026, and the full enforcement of the Digital Personal Data Protection (DPDP) Act, relying on black-box models hosted in US data centers is no longer just a privacy risk—it is a business liability.
This guide explores how Indian enterprises, particularly in banking and healthcare, are pivoting to Small Language Models (SLMs) running on private, local infrastructure.
The Case for Sovereign AI: Why Leave GPT-4?
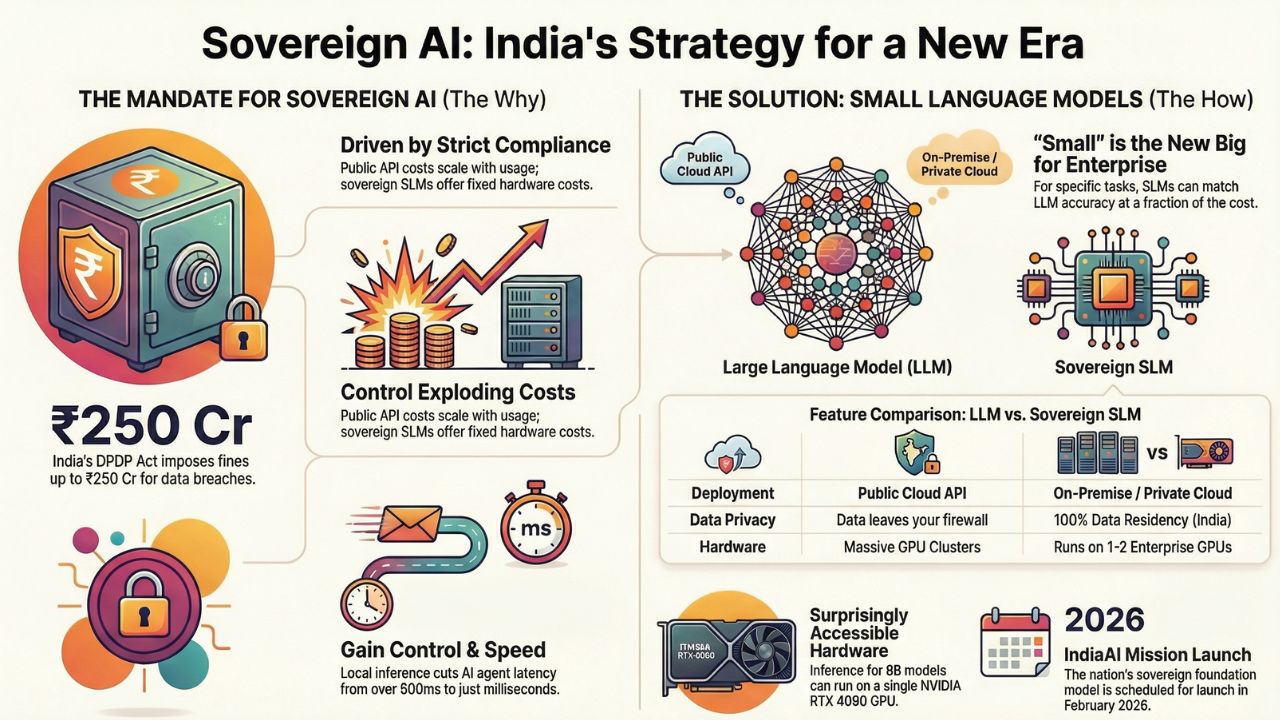
The shift to Sovereign AI is driven by three "Cs": Compliance, Cost, and Control.
- Compliance (DPDPA 2023): The Act imposes penalties up to ₹250 Cr for data breaches. "Data Fiduciaries" (you) are liable even if the breach happens at the "Data Processor" (your AI provider). Sovereignty means your data never leaves your VPC (Virtual Private Cloud).
- Cost Stability: Public API costs scale linearly with usage. If your AI agent succeeds and hits 1 million transactions, your API bill explodes. With Sovereign SLMs, your cost is fixed to the hardware you rent or own.
- Latency: For Agentic AI, a round-trip to a US server adds 500ms-1s of latency. Local inference on an Indian sovereign cloud (like Yotta or CtrlS) cuts this to milliseconds.
SLMs vs. LLMs: Why "Small" is the New Big for Enterprise
In 2026, the obsession with parameter count is over. Enterprise benchmarks show that for specific tasks—like summarising a loan application or extracting data from a GST invoice—a 7B parameter model often matches a 100B parameter model in accuracy, while being 10x cheaper to run.
| Feature | LLM (e.g., GPT-4, Gemini Ultra) | Sovereign SLM (e.g., Llama 3 8B, Mistral) |
|---|---|---|
| Deployment | Public Cloud Only (API) | On-Premise / Air-Gapped |
| Data Privacy | Data leaves your firewall | 100% Data Residency (India) |
| Hardware Req | Requires massive H100 Clusters | Runs on Consumer GPUs or CPU |
| Use Case | Creative writing, General Knowledge | RAG, Data Extraction, Specific Agents |
The Hardware Stack: Running Llama 3 Locally
One of the biggest myths is that you need million-dollar hardware to run Sovereign AI. While training a model requires massive compute, inference (running the model) is surprisingly accessible.
Recommended Specs for Enterprise Inference (2026 Standard)
1. For Small Models (7B - 8B Parameters)
Perfect for chatbots, document search (RAG), and internal tools.
- GPU: 1x NVIDIA L40S or RTX 4090 (24GB VRAM).
- RAM: 64GB System RAM.
- Storage: NVMe SSDs (Fast loading is critical for agents).
2. For Medium Models (70B Parameters)
Required for complex reasoning, coding agents, and multi-step logic.
- GPU: 2x NVIDIA A100 (80GB) or 4x A6000 Ada.
- Quantization: By using 4-bit quantization, you can fit these models into smaller VRAM footprints with negligible loss in intelligence.
Strategic Implementation: The "Air-Gap" Strategy
For Banking, Insurance, and Defense sectors in India, the "Air-Gapped" deployment is the gold standard.
- Download & Audit: Download open-weight models (Llama 3, Phi-3, Gemma) and scan them for vulnerabilities.
- Fine-Tune Locally: Use QLoRA (Quantized Low-Rank Adaptation) to fine-tune the model on your proprietary data without needing a supercomputer.
- Host on Private Cloud: Deploy the model using containerized services (like vLLM or TGI) on Indian sovereign cloud providers like Yotta Shakti Cloud, CtrlS, or NxtGen.
Frequently Asked Questions (FAQ)
A: The DPDPA does not explicitly ban foreign APIs, but it imposes strict liability on "Data Fiduciaries" for cross-border data transfers. If you send sensitive customer PII to an OpenAI server in the US, you must ensure their processing standards match Indian law. For banking and healthcare, most leaders are choosing sovereign (local) deployments to eliminate this risk entirely.
A: For a 70B parameter model, you need approximately 48GB to 80GB of VRAM (e.g., 2x NVIDIA A6000 or 1x A100). However, for Small Language Models (8B parameters), you can run inference on standard enterprise servers with a single NVIDIA L40S or even high-end consumer GPUs (RTX 4090) with 24GB VRAM.
A: The Government of India is scheduled to launch its sovereign AI model (often referred to as 'Bharat Gen' or the 'National LLM') in February 2026, alongside a subsidized compute infrastructure (GPU clusters) for Indian startups and enterprises.

Sources & References
- Sovereign AI India: Nation Readies Homegrown Model by February 2026
- India's Digital Personal Data Protection Act 2023 brought into force
- India | Jurisdictions - DataGuidance (DPDPA Penalties)
- LLaMA 3.3 System Requirements: What You Need to Run It Locally
- GPU Hardware Requirement Guide for Llama 3 in 2025
- SLM vs. LLM: Differences & Choosing the Best AI Model in 2026
- DDN Launches Sovereign AI Solutions based on NVIDIA AI Data Platform
- India's sovereign AI vision with NxtGen and Red Hat