RAGAS vs. DeepEval vs. TruLens: The 2026 Showdown (Cost & Latency Analysis)

In the "Agentic Era" of 2026, the question is no longer "Does the model work?" The question is "Does the model work efficiently, and can we prove it automatically?"
Choosing an evaluation framework for your AI Agents is a strategic decision that impacts your cloud bill and your deployment speed. A framework that is too slow will bottle-neck your CI/CD pipeline. A framework that is too token-hungry will bloat your testing budget.
We evaluated the three industry heavyweights—RAGAS, DeepEval, and TruLens—not just on their ability to detect hallucinations, but on their operational metrics: Cost per Eval and Latency per Run.
1. The Three Titans of AI Evaluation
Before diving into the metrics, let's define the core philosophy of each tool as they stand in 2026.
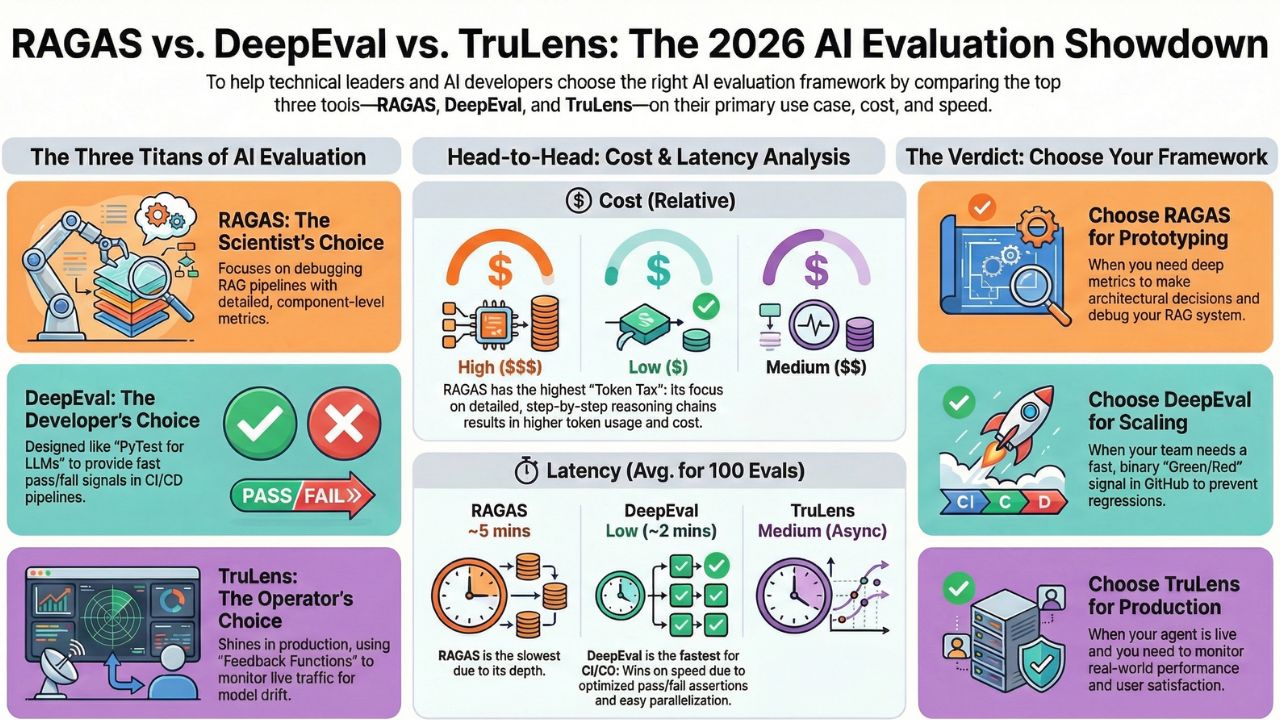
- RAGAS (Retrieval Augmented Generation Assessment): The Scientist's Choice. RAGAS focuses on component-level metrics. It doesn't just say "The answer is bad"; it mathematically proves whether the failure was in the Retriever (Context Precision) or the Generator (Faithfulness).
- DeepEval: The Developer's Choice. Often called the "PyTest for LLMs". It is designed to fit seamlessly into GitHub Actions, treating LLM outputs like unit tests with binary pass/fail thresholds.
- TruLens: The Operator's Choice. While it handles offline testing, TruLens shines in Observability. Its "Feedback Functions" are architected to run on live production traffic to detect drift over time.
2. The Comparison Matrix (2026 Edition)
We ran a standard regression suite of 100 Q&A pairs through all three frameworks using GPT-4o as the "Judge" model. Here is how they stacked up.
| Feature | RAGAS | DeepEval | TruLens |
|---|---|---|---|
| Primary Use Case | RAG Pipeline Debugging | CI/CD Blocking (Unit Tests) | Production Monitoring |
| Setup Difficulty | Medium (Academic) | Low (Developer Friendly) | Medium (Instrumentation) |
| Avg Latency (100 Evals) | High (~5 mins) | Low (~2 mins) | Medium (Async) |
| Token Cost (Relative) | $$$ (Detailed Reasoning) | $ (Optimized Assertions) | $$ (Feedback Loops) |
| Ecosystem | LangChain Native | Standalone / CI Native | Snowflake / Enterprise |
3. Deep Dive: The "Token Tax" (Cost Analysis)
Why is there such a cost difference? It comes down to the prompt engineering of the framework itself.
RAGAS: The High Cost of Precision
RAGAS prioritizes explainability. When it calculates a "Faithfulness" score, it asks the Judge model to extract statements, cross-reference them with the context, and generate a step-by-step reasoning chain. This results in long context windows and higher output token usage. It is excellent for debugging why an agent failed, but expensive to run on every commit.
DeepEval: Optimized for "Pass/Fail"
DeepEval allows for "Assert" logic. By optimizing the prompt for a binary outcome (Pass/Fail) rather than a nuanced essay, it drastically reduces the number of output tokens. For a CI/CD pipeline running 50 times a day, DeepEval offers the best Unit Economics.
4. Deep Dive: Latency & CI/CD Blocking
Speed is the killer in Eval-Driven Development. If your developers have to wait 20 minutes for the "AI Test Suite" to finish, they will stop running it.
DeepEval wins here due to its parallelization capabilities. It allows you to shard the evaluation dataset across multiple threads easily within the CI runner. TruLens takes a different approach: it is often best used "Deferred." You merge the code, deploy to staging, and TruLens evaluates the interactions asynchronously, alerting you on Slack if quality drops.
5. The Verdict: Which one should you choose?
The "Best" tool depends on where you are in the Agentic Lifecycle:
- Choose RAGAS if: You are in the Prototyping Phase. You are trying to figure out if you should use a Vector DB or a Knowledge Graph. You need detailed metrics to make architectural decisions.
- Choose DeepEval if: You are in the Scaling Phase. You have a team of 10 engineers pushing code daily. You need a fast, binary "Green/Red" signal in GitHub Actions to prevent regressions.
- Choose TruLens if: You are in the Production Phase. Your agent is live. You need to know if the new model update caused user satisfaction to drop in the real world.
6. Frequently Asked Questions (FAQ)
A: DeepEval is generally the most cost-effective for CI/CD because it is optimized for 'Unit Testing' logic. It allows you to use smaller, cheaper judge models for binary pass/fail checks, whereas RAGAS often defaults to more expensive, detailed reasoning chains.
A: Yes, but it shines in online production monitoring (Observability). TruLens Feedback Functions are designed to run asynchronously on live traffic to detect drift, while RAGAS and DeepEval are better suited for pre-production 'Golden Dataset' testing.
A: RAGAS (Retrieval Augmented Generation Assessment) pioneered the component-wise evaluation approach. It mathematically separates 'Retriever' performance (Context Precision) from 'Generator' performance (Faithfulness), making it indispensable for debugging RAG pipelines.
A: Not strictly, but highly recommended for the 'Judge' model. While all three support open-source models (like Llama 3), the accuracy of the evaluation drops significantly. For production-grade assertions, the cost of GPT-4o as a judge is usually justified.
