How to Build a "Golden Dataset" for Agent Testing (Step-by-Step Guide)

- Updated prompt engineering techniques to reflect OpenAI's latest instruction-following guidelines for structured JSON output.
- Added details on generating multi-turn conversational datasets.
- Expanded the Python code block to include asynchronous requests for faster dataset generation.
The biggest bottleneck in deploying Generative AI isn't the underlying model architecture—it's the Evaluation Gap. As engineering teams transition from static code to probabilistic systems, they quickly learn a harsh lesson: you cannot improve what you cannot measure.
To accurately measure an AI Agent's performance, particularly in Retrieval-Augmented Generation (RAG) workflows, you need a "Golden Dataset": a trusted, version-controlled repository of Questions and Verified Answers representing absolute Ground Truth.
Relying on manual data entry to write 150+ QA pairs based on your internal documentation is a strategy doomed to fail. It is tedious, unscalable, and inherently biased toward the specific edge cases the human author happens to remember. In this guide, we will demonstrate how to automate this process rapidly and accurately using a technique called Synthetic Data Amplification.
The Evaluation Gap: Why Manual Testing Fails
When you rely on manual testing ("vibes-based" evaluation), an engineer types a prompt into a user interface, reads the output, and subjectively decides if it looks correct. This approach fails for three reasons:
- Lack of Regression Testing: If you update your embedding model or tweak the system prompt, you cannot manually re-test thousands of historical edge cases.
- Coverage Blind Spots: Human testers naturally stick to "happy path" scenarios. They rarely think to ask the questions a confused or malicious user might input.
- Subjectivity: What constitutes a "good" answer? Without a documented baseline, quality is entirely subjective. This is why testing tools like Selenium are dead for AI testing.
What Exactly is a Golden Dataset?
In the context of RAG evaluation, a Golden Dataset is essentially a structured table (often CSV or JSON) consisting of at least three core columns:
- Input (The Query): The specific question the user asks. For example, "How do I reset my production API key if I lose my MFA device?"
- Context (Optional but Recommended): The exact document chunk or database record that contains the factual information required to answer the query.
- Ground Truth: The ideal, factually unassailable answer your agent must output to be considered correct.
This dataset becomes your North Star. If your agent's response deviates semantically from the Ground Truth, or if it introduces facts not present in the Context, it triggers an alert.
The 3-Step Pipeline to Synthetic Amplification
Generating a Golden Dataset from scratch is daunting. We solve this by leveraging Frontier Models (like GPT-4o or Claude 3.5 Sonnet) as data generators, acting on your proprietary documents.
Extract the "Seed" Data
Do not start from a blank page. Extract "Seed Data" directly from your existing knowledge base or historical user interactions. The quality of your synthetic dataset is strictly bound by the quality of your seed data.
Excellent sources for seed data include:
- Customer Support Logs: Export raw Zendesk or Intercom transcripts. This captures how users actually speak, including typos and colloquialisms.
- Chunked Documentation: If you are building a RAG system, you already have chunked PDFs or Markdown files. Use these chunks as the foundational truth.
Synthetic Amplification (The Code)
Next, we use an LLM to "read" your seed content and generate hundreds of diverse test cases. We want the model to generate simple questions, multi-step reasoning questions, and adversarial questions.
Here is an asynchronous Python snippet using the OpenAI SDK to generate structured JSON QA pairs from a text chunk. Enforcing JSON output guarantees we can parse it easily into our testing framework.
import asyncio
from openai import AsyncOpenAI
import json
client = AsyncOpenAI()
# The prompt forces structured output based on the provided context
GENERATION_PROMPT = """
You are an expert QA Automation Engineer.
Given the following context from an internal technical document, generate
THREE diverse user questions (one simple, one complex reasoning, one conversational)
and the correct Ground Truth answers based ONLY on this text.
Context: {context_chunk}
Respond STRICTLY with valid JSON in the following format:
{
"test_cases": [
{
"type": "simple|complex|conversational",
"question": "...",
"ground_truth": "..."
}
]
}
"""
async def generate_synthetic_data(context_chunk):
response = await client.chat.completions.create(
model="gpt-4o",
response_format={ "type": "json_object" },
messages=[{"role": "user", "content": GENERATION_PROMPT.format(context_chunk=context_chunk)}]
)
return json.loads(response.choices[0].message.content)
The "Curator-in-the-Loop" Verification
Crucial Step: Synthetic data generators can and will hallucinate. You must have a human—specifically, a Subject Matter Expert (SME)—review the generated output.
They do not need to write the answers from scratch; they simply need to Verify them. They scan the CSV, flag any Ground Truth answers that contain errors, rewrite them if necessary, and approve the rest. This workflow reduces the time-to-test by 90% while maintaining absolute factual integrity.
Expanding Your Dataset for Edge Cases
A dataset filled only with perfect, clearly worded questions will give you a false sense of security. Real users are messy. To build a robust dataset, instruct your synthetic generator to introduce noise:
- Add Typos and Slang: Test if your retriever can handle "hw do i rset pasword" instead of just "How do I reset my password?"
- Multi-Turn Context: Generate datasets where the user asks a follow-up question that relies on the previous answer (e.g., "Okay, now how do I delete it?").
- Out-of-Domain Constraints: Add questions entirely unrelated to your product. The Ground Truth should explicitly mandate that the agent politely refuses to answer, ensuring you can test your safety guardrails.
Next Steps: Automating the Evals
Once your Subject Matter Experts have verified the CSV file, you possess a true Golden Dataset. You are now ready to feed this data into an evaluation framework to automate your CI/CD pipeline. By employing LLM-as-a-Judge automation, you can run hundreds of regression tests on every pull request without human intervention.
Next: Choose Your Evaluation Framework Read our deep-dive comparison of RAGAS, DeepEval, and TruLens to determine the most cost-effective tool for your specific pipeline architecture.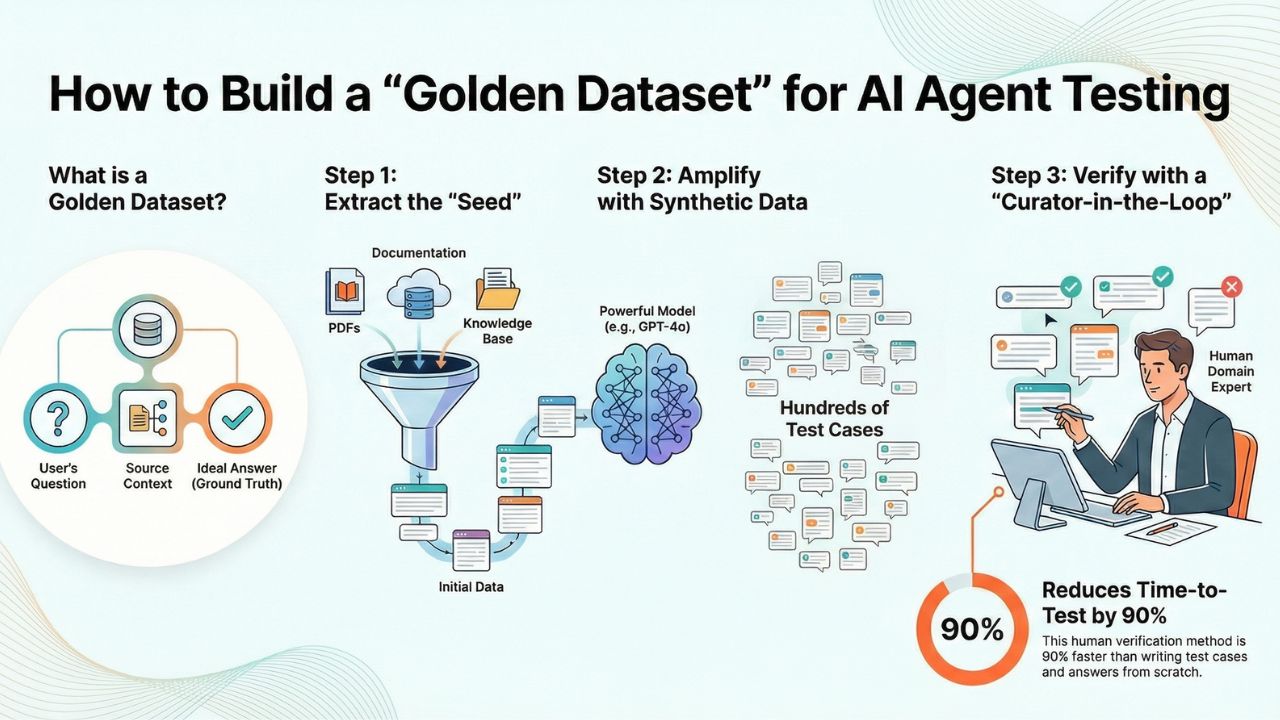
Frequently Asked Questions
A: A Golden Dataset is a curated collection of input questions and verified "Ground Truth" answers. It serves as the unshakeable benchmark against which your AI agent's retrieval and generation performance is mathematically measured.
A: For a reliable directional signal during prototyping, aim for a minimum of 50 pairs. For complex, production-grade enterprise agents, 150-200 diverse pairs covering different topics, edge cases, and query complexities are highly recommended.
A: Yes, this is known as Synthetic Data Generation. However, you must implement a "Curator-in-the-Loop" workflow. A human must verify the accuracy of the AI-generated answers before they become the standard; otherwise, you risk encoding hallucinations into your baseline.
A: Every time your underlying documentation, product features, or compliance requirements change significantly. Treat your Golden Dataset exactly like application source code—it requires strict versioning and continuous maintenance. Furthermore, as you monitor real-world interactions using an AI drift detection playbook, you should feed novel user queries back into your Golden Dataset.

References & Further Reading
- Textbooks Are All You Need (Microsoft Research) - On the power of high-quality synthetic data for training and evaluation.
- LangChain QA Documentation - Implementation details for robust RAG architectures.
- OpenAI on Instruction Following - Best practices for prompting frontier models to generate predictable, structured data outputs.