Engineering the "Right to Forget": Machine Unlearning & Vector DB Strategy

For Data Scientists and Vector DB Admins, Section 12 of the DPDP Act ("Right to Erasure") presents the hardest engineering problem of 2026. In the SQL world, a deletion request is a simple DELETE FROM users WHERE id = 'xyz'. In the world of High-Dimensional Vectors and LLM Weights, it is a nightmare.
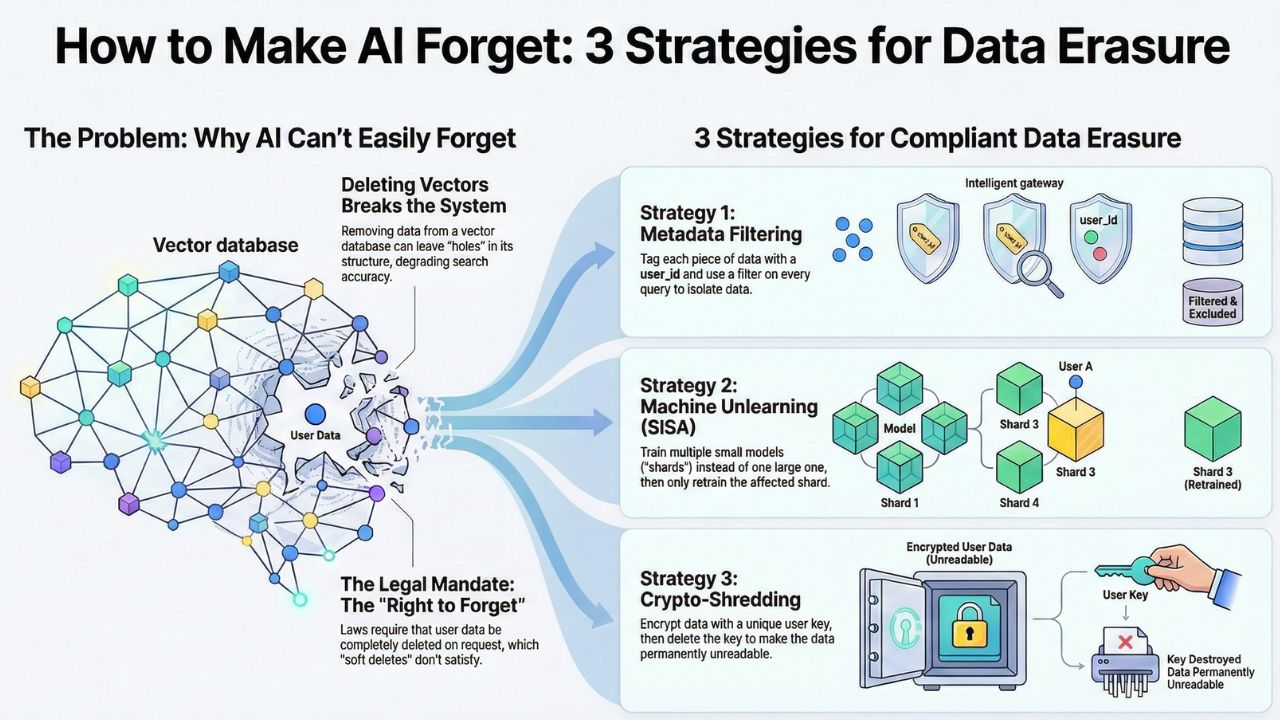
Once a user's data is embedded into a dense vector space or baked into the weights of a neural network, extracting it is akin to trying to remove a specific cup of sugar from a baked cake. This guide outlines three architectural patterns to solve this.
1. The Vector Problem: Why SQL Logic Fails
Vector Databases (like Pinecone, Milvus, Weaviate) use Approximate Nearest Neighbor (ANN) algorithms like HNSW (Hierarchical Navigable Small World). These structures rely on a carefully constructed graph of nodes.
The Issue: "Hard Deleting" a node often leaves a "hole" in the graph, degrading search accuracy for everyone else. Consequently, many DBs only mark data as "deleted" (Soft Delete) and only remove it during a periodic "compaction" or "re-indexing" event—which might take days.
2. Strategy A: Metadata Filtering (The RAG Approach)
If you are building a Retrieval-Augmented Generation (RAG) system, do not rely on the vector index as your source of truth. The most compliant architecture is "Logical Separation."
Implementation:
- Namespace Isolation: Store every customer's vectors in a distinct `namespace` (Pinecone) or `tenant` (Weaviate). When they leave, you drop the entire namespace.
- Filter-First Search: Attach a `user_id` to every vector metadata. Enforce a hard filter on every query:
# Pinecone Example: Compliance Filtering
index.query(
vector=[0.1, 0.2, ...],
filter={
"user_id": {"$eq": "user_123"}, # Mandatory Filter
"is_active": {"$eq": true}
},
top_k=5
)3. Strategy B: Machine Unlearning (SISA)
If you are fine-tuning models, you cannot filter metadata. You need SISA (Sharded, Isolated, Sliced, Aggregated) training.
Instead of training one massive model on 100% of data, you train 10 smaller models (shards) on 10% of the data each. When `User A` (whose data is in Shard 4) requests deletion, you only retrain Shard 4. This reduces compute costs by 90%.
4. Strategy C: The "Crypto-Shredding" Approach
This is the "Nuclear Option" for immutable logs or blockchain-based AI ledgers. It relies on the principle that inaccessible data is equivalent to deleted data.
The Workflow:
- Generate a unique symmetric key for every user (`key_user_123`).
- Encrypt their sensitive text before embedding it.
- Store the encrypted blob in the Vector DB (vectors are derived from the cleartext, but the stored payload is encrypted).
- On Deletion Request: Delete `key_user_123` from your Key Management System (KMS).
The vector remains in the index, but the retrieved context is cryptographic gibberish, rendering it useless to the LLM.
Frequently Asked Questions (FAQ)
Not efficiently. In Vector DBs like Pinecone using HNSW indexes, deleting a node can corrupt the graph structure. It often requires a costly re-indexing process or "soft deletion" marks that persist until compaction.
Machine Unlearning is the process of removing the influence of a specific data point from a trained machine learning model without retraining the entire model from scratch.
Yes. Most legal interpretations accept that if data is rendered "mathematically impossible" to recover (by deleting the encryption key), it satisfies the requirement for erasure.

Sources & References
- Google Research: Machine Unlearning (SISA Framework).
- Pinecone Engineering Blog: Handling Deletions in HNSW Indexes.
- Weaviate Docs: Multi-Tenancy and Data Isolation for GDPR/DPDP.
- NIST Privacy Framework: Guidelines on Cryptographic Erasure.