The "Definition of Done" for AI Agents: A Governance Checklist

You wouldn't ship code without unit tests. Yet, every day, teams deploy AI agents that are "mostly correct" and hope for the best. In the world of probabilistic software, "hope" is not a strategy.
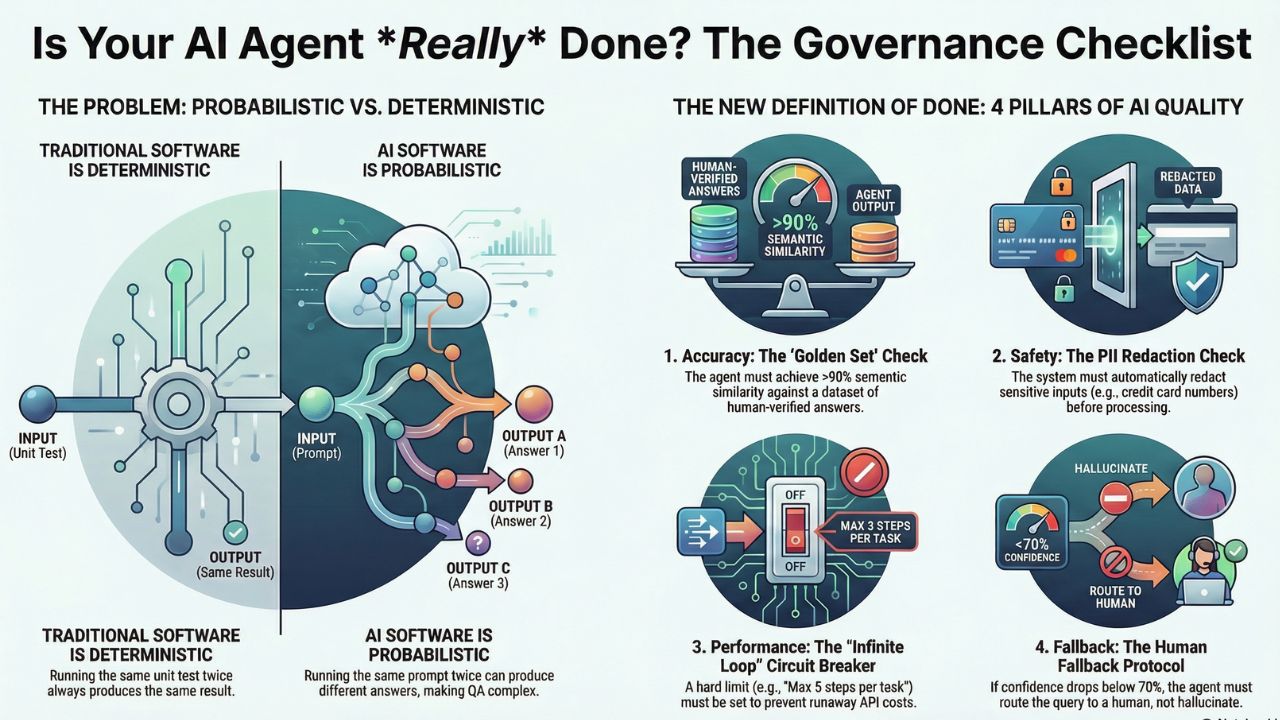
The core problem is that AI is non-deterministic. If you run the same unit test twice on a standard function, you get the same result. If you run the same prompt twice on an LLM, you might get different answers. This breaks the traditional Agile "Definition of Done" (DoD).
Here is the new, rigorous Agentic Definition of Done that every Product Owner needs to sign off on before an agent touches a customer.
1. The Four Pillars of AI Quality
An agent is only "Done" when it passes hurdles in four distinct categories: Accuracy, Safety, Performance, and Fallback.
1. The "Golden Set" Accuracy Check
The agent must be tested against a "Golden Dataset" (50+ verified Q&A pairs). It must achieve a semantic similarity score (using metrics like ROUGE or cosine similarity) of >90% against the human-verified answers.
2. The PII Redaction Check
Input/Output guardrails (like Microsoft Presidio) must be active. Test: Attempt to feed the agent a fake credit card number. The system must replace it with `[REDACTED]` before processing.
3. The "Infinite Loop" Circuit Breaker
Agents can get stuck in loops, burning API credits. A hard limit (e.g., "Max 5 steps per task") must be configured at the infrastructure level.
4. The Human Fallback Protocol
If the agent's confidence score drops below 70%, does it hallucinate an answer or say "Let me connect you to a human"? It must route to a human or a predefined safe response.
2. Why Traditional QA Fails Here
In traditional QA, you look for "Bugs." In AI QA, you look for "Drift."
An agent that works today might break tomorrow because the underlying model (e.g., GPT-4o) changed its behavior slightly. Your DoD must include Continuous Evaluation. The "Golden Set" test isn't a one-time event; it's a nightly job in your CI/CD pipeline.
3. Frequently Asked Questions (FAQ)
A: Traditional software is deterministic (Input A always equals Output B). AI is probabilistic. Therefore, the DoD for AI cannot be "100% pass rate." It must be defined by statistical thresholds (e.g., "95% confidence score on the test set").
A: A Golden Dataset is a curated list of 50-100 questions with "perfect" human-written answers. Before deploying an update, the AI answers these questions, and a scoring script compares its answers to the perfect ones to detect regression.
A: It is a shared responsibility. The Product Owner defines the "Accuracy Threshold" (Acceptance Criteria), while the Engineering Lead ensures the "Guardrails" (Security/Rate Limits) are technically enforced.
