Context Engineering Cuts Agent Failures by 60%
- Context over Prompts: Prompt engineering dictates behavior; context engineering provides the factual reality required to execute that behavior accurately.
- Pipeline Design: A robust retrieval pipeline design filters out irrelevant data before the model ever sees it, drastically reducing token waste and hallucinations.
- Preventing Context Rot: Without aggressive agent state management, conversation histories bloat and older instructions decay, causing the agent to "forget" its constraints.
- Strategic Assembly: Effective RAG context assembly treats the context window as a highly constrained database, prioritizing relevancy scoring over sheer volume.
Most agent failures aren’t model failures. When an AI agent skips a critical compliance step or hallucinates a policy, engineering teams often blame the large language model (LLM).
In reality, the model processed the exact chaos it was fed.
Context engineering for production agents fixes the real cause of unreliability: the noisy, degraded pipeline of information most teams skip building.
Relying on a foundation of deterministic guardrails for AI agents forces you to control the workflow.
But controlling the workflow is useless if the agent is making decisions based on stale, conflicting, or bloated information.
Context engineering is the discipline of precisely assembling the agent's reality.
When you shift from endlessly tweaking prompts to engineering the context pipeline, failure rates plummet.
By tightly managing the context window and preventing noise from entering the prompt, enterprise teams routinely see a 60% reduction in logic and routing errors.
Why Most Agent Failures Aren't Model Failures
When an agent derails, the instinct is to write a longer, stricter system prompt. This rarely works.
Large language models are highly sensitive to the signal-to-noise ratio within their working memory.
If you feed an agent a 100-page unstructured PDF and ask it to approve a refund, the model's reasoning capabilities are suffocated by the noise.
Agent failures in production are overwhelmingly retrieval and context failures. The model didn't malfunction; it accurately reasoned over bad data.
Fixing this requires shifting focus from the symptom to the root cause.
If you are constantly patching up hallucination symptoms, you are likely ignoring the underlying context pipeline.
Context engineering treats the input data as a highly structured, engineered asset rather than a messy dumping ground.
What Does a Context Engineering Pipeline Include?
A production-grade context engineering pipeline is an automated system that decides exactly what the model needs to know right now, and nothing more.
It acts as an aggressive filter between your enterprise data and the LLM.
This pipeline operates on strict rules, unlike the trial-and-error approach found when comparing context engineering to vibe coding workflows.
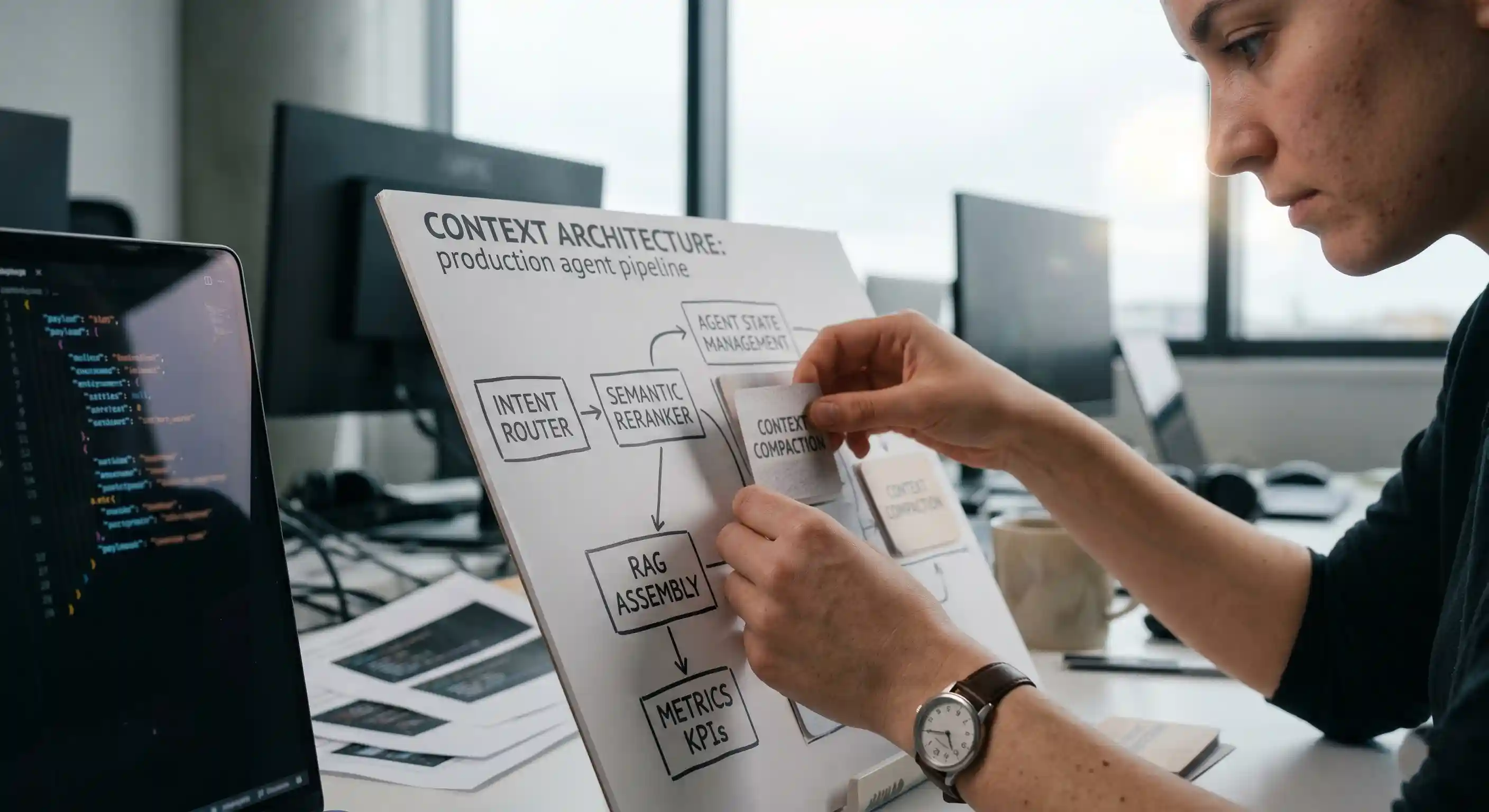
RAG Context Assembly
Retrieval-Augmented Generation (RAG) is just the beginning. True RAG context assembly doesn't just dump search results into a prompt.
It involves reranking chunks, formatting them into clear XML or JSON structures, and injecting them into specific, predefined slots within the agent's memory.
By structuring the context, you give the LLM clear boundaries between "instructions," "user input," and "retrieved facts."
Context Window Management
The context window is your agent's short-term memory limit. Just because a model accepts 128k tokens doesn't mean you should fill it.
Context window management is the practice of keeping the prompt as lean as possible.
LLMs suffer from the "lost in the middle" phenomenon. Information placed at the very beginning or end of a prompt is recalled perfectly, while facts buried in the middle degrade.
Engineering the window means placing critical constraints at the extreme ends of the prompt.
Agent State Management and Context Rot
As an autonomous agent executes a multi-step task, its history grows. If unmanaged, this history causes context rot.
Old, resolved tool calls and conversational dead-ends clog the working memory, confusing the model about its current objective.
Effective agent state management involves compacting memory. Instead of keeping a verbatim transcript of the last 20 steps, the pipeline summarizes resolved tasks into a single "current state" paragraph, freeing up tokens for the next crucial decision.
Metrics for Measuring Context Quality
You cannot improve what you cannot measure. Measuring context engineering requires distinct metrics separated from general model evaluation.
- Context Relevance: What percentage of the injected data was actually necessary to complete the task?
- Token Efficiency: Are you achieving the same accuracy while consuming fewer tokens per call?
- Retrieval Precision: How often does the retrieval pipeline return the correct chunk in the top 3 results?
By tracking these specific KPIs, engineering teams can tune their pipelines to deliver clean, dense context, directly lowering API costs while boosting agent obedience.

Frequently Asked Questions (FAQ)
Context engineering is the technical discipline of designing, filtering, and structuring the exact information an AI agent receives before making a decision. It focuses on optimizing the retrieval pipeline and memory state to ensure the agent operates on clean, relevant data.
Prompt engineering focuses on phrasing instructions to guide model behavior. Context engineering focuses on the data payload the model reasons over. Prompts dictate how to act; context dictates what facts to act upon.
A robust pipeline includes intent routing, vector retrieval, semantic reranking, context assembly (formatting chunks into structured templates), and state management (compacting past memory to prevent window bloat).
Language models are probability engines highly sensitive to noise. High-quality, dense context increases the probability of a correct, compliant action. Poor context introduces distracting variables, leading the agent to hallucinate or ignore its primary constraints.
Context rot occurs when an agent's memory fills with irrelevant past conversation turns or resolved tool outputs, degrading its focus. Prevent it by implementing memory compaction, which summarizes past steps into a concise current state.
An agent should receive the absolute minimum context required to complete the immediate next step. Maximizing the context window unnecessarily increases latency, drives up token costs, and raises the likelihood of the model losing critical instructions in the noise.
Use rolling memory windows and tiered storage. Keep only the immediate task parameters and the last 2-3 conversational turns in the active context window. Offload older interactions to a vector database for retrieval only if explicitly needed.
Common mistakes include relying on naive RAG that dumps unranked chunks into the prompt, failing to separate instructions from retrieved data using structured formatting, and ignoring memory compaction during long multi-step workflows.
Hallucinations often occur when a model lacks specific facts and fills the void with probabilistic guesses. By engineering a reliable retrieval pipeline, you ground the model in verified enterprise data, eliminating the knowledge gap that causes fabrication.
Key metrics include Context Relevance (the ratio of useful tokens to noise), Token Efficiency (accuracy per token spent), and Mean Reciprocal Rank (MRR) for the retrieval pipeline to ensure the most vital data appears at the top of the prompt.